
MapReduce 基础操作

简介
MapReduce是一种分布式计算框架,用于处理大规模数据集的计算问题。它是由 Google 公司开发的,旨在简化并行计算的开发。
在MapReduce中,计算问题被分解成两个阶段:映射(Map)和归约(Reduce)。映射阶段将输入数据划分成小的数据块,并将每个数据块映射到一组键值对。然后,这些键值对被传递给归约阶段,归约阶段对键值对进行分组,并对每组执行归约操作,生成最终结果。
MapReduce的优点是它可以在大规模计算集群上高效地并行运行,而无需开发人员关心底层的并发细节。这使得开发人员可以更专注于算法设计和问题解决,而不是处理并发和分布式系统的复杂性。
前提:确保配置好 Hadoop 环境
其中 MapReduce 对应 <HADOOP_HOME>/etc/hadoop/mapred_site.xml配置文件:
(我的HADOOP_HOME是/usr/local/hadoop则对应)
1 | <!-- mapred_site.xml --> |
启动服务
进入 Hadoop 用户(取决于个人配置,没添加用户就不用)
$ su hadoop启动 ssh
$ sudo service ssh start链接本地服务
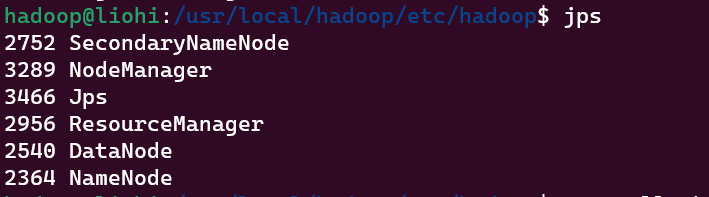
$ ssh localhost启动服务
$ start-all.shjps 查看,显示如下则启动成功

编写 WordCount.java
创建工作文件夹
1
2
3cd /usr/local/hadoop
sudo mkdir hadoop-demo
sudo chmod -R 777 hadoop-demo # 修改权限编写
WordCount.java$ vi WordCOunt.java1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
打包成 JAR 文件
1 | /hadoop-demo |
若出现
error: package org.apache.hadoop.conf does not exist等错误可能是Hadoop环境变量没配好解决:
sudo vi ~/.bashrc添加以下行
2
3
export HADOOP_HOME=/path/to/hadoop
export HADOOP_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
source ~/.bashrc
创建测试文件并运行
创建一个`input.txt``
vi input.txt随便写点东西…(推荐写几个重复的单词,空格分开,这样结果更直观)
1
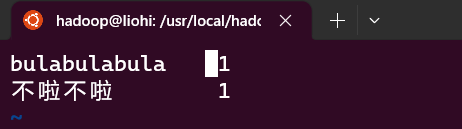
bulabulabula 不啦不啦
将 input.txt 上传到 HDFS 文件系统 (HDFS 文件读写搜索历史文章有介绍)
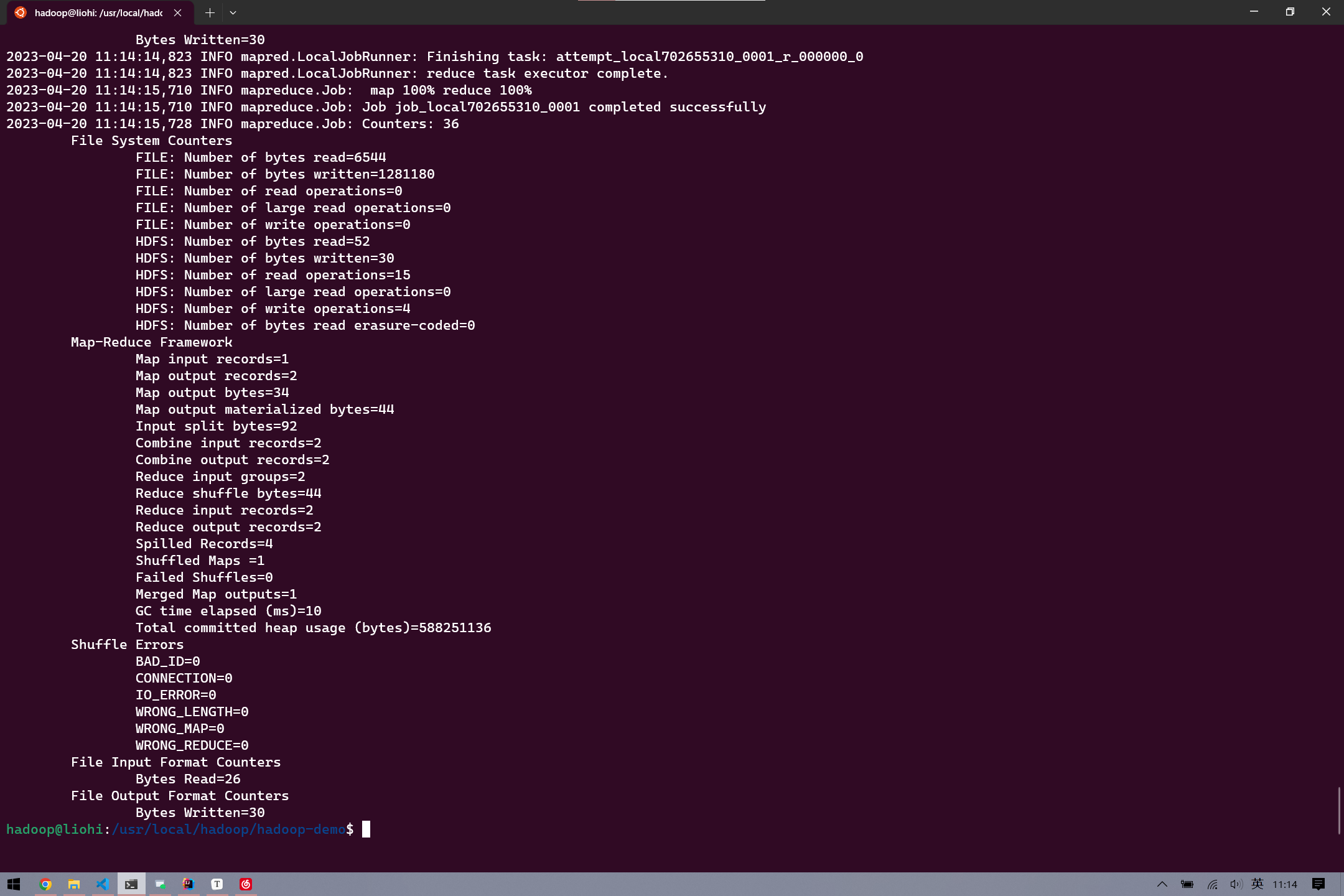
$ hdfs dfs -put input.txt /test1提交 MapReduce 作业
$ hadoop jar wordcount.jar WordCount /test1 /output将 output 从 HDFS 系统提取出来
hdfs dfs -get /output out查看一下
1
2
3
4
5cd out
# 可以看到_SUCCESS 和part_r_00000
vi part_r_00000两个单词分别 1 个(当然在测试文件里可以创建几个重复的单词更直观)
Over!
- 标题: MapReduce 基础操作
- 作者: liohi
- 创建于 : 2023-04-20 11:26:51
- 更新于 : 2023-04-27 19:47:10
- 链接: https://liohi.github.io/2023/04/20/MapReduce安装和配置/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。